Misclassification of binary outcome data can lead to biased estimates of model coefficients when using logistic regression. In certain situations where we have information on the stucture of the misclassification problem there exist methods to estimate bias-corrected coefficients. Such methods can also be used in cases where we are unsure of the exact structure of the misclassification problem and wish to perform sensitivity analyses.
Measurement error
In a misclassified binary outcome setting, rather than observing the true outcome of interest \(Y\), we observe \(Y^*\). Our goal is to estimate the impact of covariates \(X\) on the outcome \(Y\) using logistic regression, with particular interest in the covariate coefficients \(\beta_X\):
\[P(Y=1|X=x_i) = \sigma(\beta_0 + \beta_X x_i)\]
Where \(\sigma(x) = 1/(1+e^{-x})\) is the logistic link function and we assume the covariates \(X\) are measured without error. An important consideration is whether the measurement error is nondifferential, where the mismeasured outcome is independent of the covariates given the true outcome:
\[Y^* \perp X | Y\]
Two key quantities in bias-correcting our coefficient estimates are the sensitivity and specificity of our measurement process. The sensitivity \(\text{sens} = P(Y^*=1|Y=1)\) or true positive rate quantifies the likelihood positive observations \(Y^*=1\) are in fact positive cases \(Y=1\). The specificity \(\text{spec} = P(Y^*=0|Y=0)\) or false positive rate quantifies the likelihood negative observations \(Y^*=0\) are in fact negative cases \(Y=0\).
Likelihood and estimation
For a study of size \(n\) the likelihood for our observed data is:
If we assume nondifferential misclassification then the second term in the likelihood can be expressed directly in terms of the sensitivity and specificity of our measurement process:
Notice how there is nothing in this final form of the likelihood that cannot be replaced by the observed data \((Y^*,X)\), or the known (or assumed) sensitivity and specificity values. This can now be directly optimised using general purpose optimisation routines in R (e.g. stats::optim), python (e.g. scipy.optimize) etc. See 5.4.4 of Shaw et al. (2020) for a list of papers that developed this methodology.
Bias corrected model fitting functions
The code below uses the above results to adjust the logistic regression fitting estimation process to account for the sensitivity and specificity of the measurement process.
Code
logistic <-function(X,betas) {1/ (1+exp(- (X %*% betas)))}nLL_mc <-function(betas,X,y,sens,spec) { n <-nrow(X) pY <-logistic(X,betas) t1 <--y*log(sens*pY + (1-spec)*(1-pY)) t2 <--(1-y)*log((1-sens)*pY + spec*(1-pY))sum(t1 + t2) }missclass_glm <-function(formula,sens,spec,data) {# initial fit ignoring missclassification b0 <-coef(glm(formula,data=data,family =binomial()))# fit accounting for sens and spec y <-model.response(model.frame(formula,data)) X <-model.matrix(formula,data) res <-optim(b0,nLL_mc,X=X,y=y,sens=sens,spec=spec,hessian=TRUE) coef <- res$par std_err <-sqrt(diag(solve(res$hessian))) z <- coef / std_err p_value <- (1-pnorm(abs(z))) *2# output list(unadjusted = b0,adjusted =data.table(var =names(coef),coef = coef,std_err = std_err,p_value = p_value,lower = coef -1.96*std_err,upper = coef +1.96*std_err))}
Simulation studies
A question for any method is how well does it work? Below we look at a few different scenarios and compare how the coefficients estimated from the bias-adjusted method compare to those estimates naively using standard logistic regression.
Data generating process
The simulated data contains five variables, three binary (A1, A2 and A3) and two continuous (X1 and X2), with A1 and X2 being the “most important” (the largest coefficients). There are no interactions and the connection between the probabilistic outcome and covariates is a straightforward logistic link.
Simulation study 1: Vary sensitivity and specificity
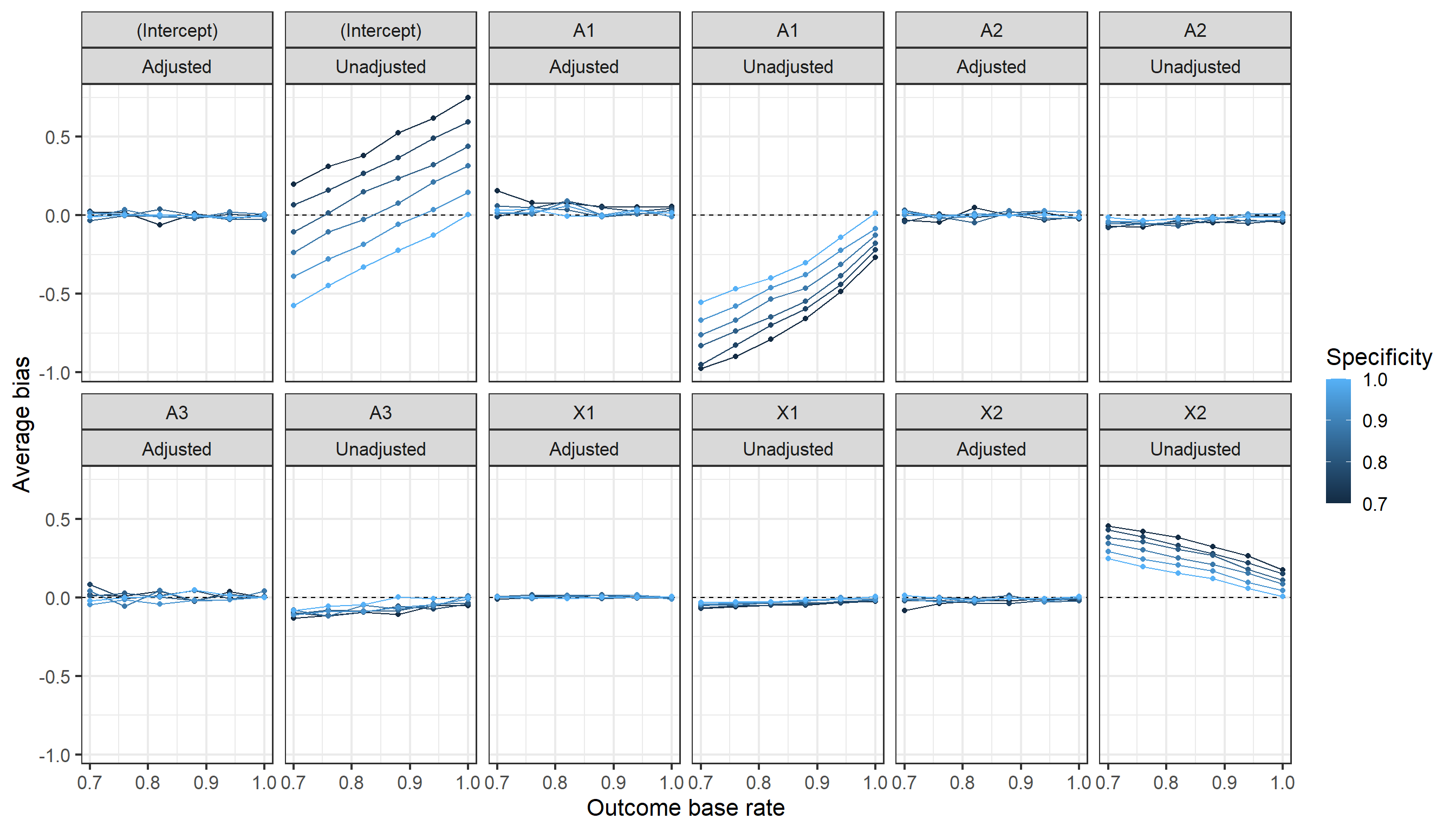
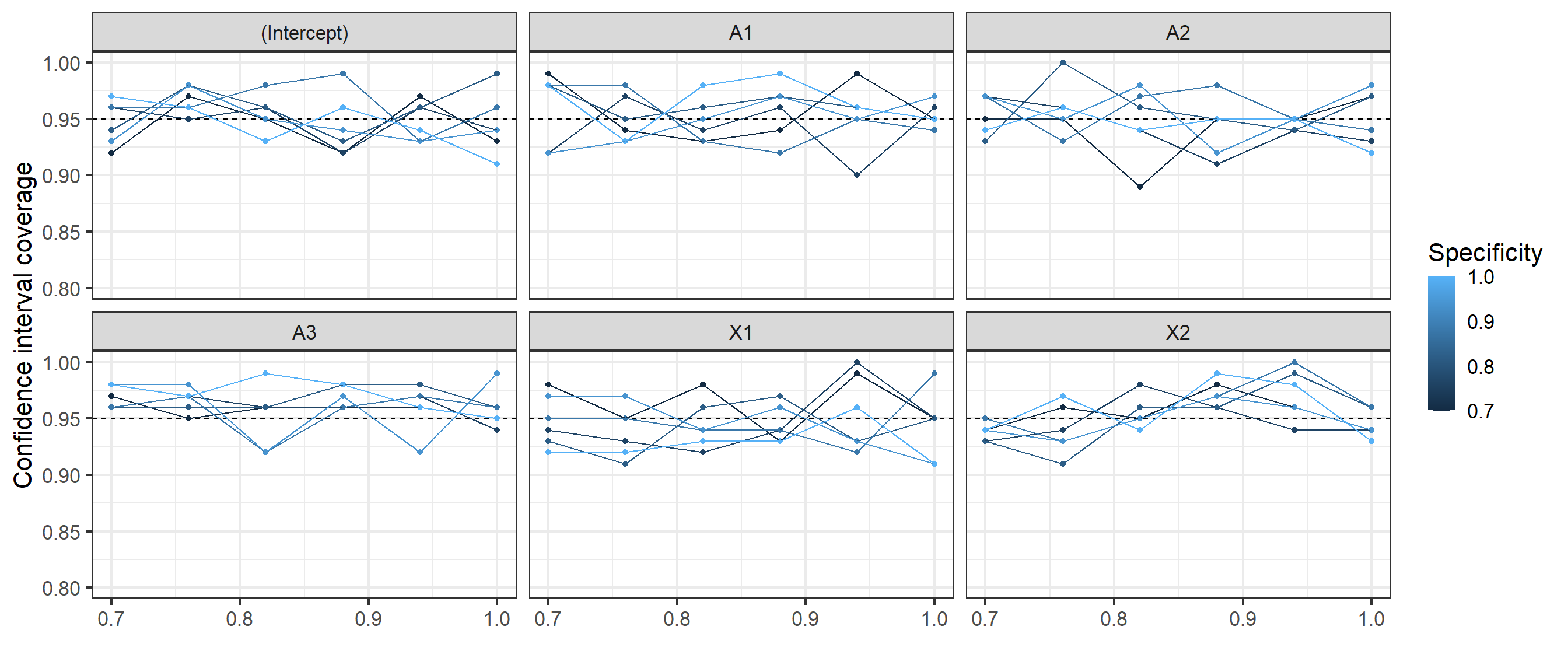
Below we vary the sensitivity and specificity of the outcome measurement process assessing the impact of this on the average bias \(B_M=\frac{1}{M}\sum_m (\hat{\beta}_m-\beta)\) across \(m=1,..,M\) simulations of the unadjusted logistic regression coefficients, and the degree to which the bias-correction estimation process accounts for any bias. We also assess the coverage of the 95% confidence intervals (Wald approximate) \(C_M=\frac{1}{M}\sum_m I_{\beta \in (\hat{\beta}_{m,\text{95% lower}},\hat{\beta}_{m,\text{95% upper}})}\) around the bias-adjusted coefficients.
As shown below the bias-adjusted coefficients perform far better than the unadjusted coefficients in capturing the true values of the data generating process (model coefficients).
The coverage of these lare sample confidence intervals appears reasonably close to 95% given the low number of simulation repetitions \(M=100\) and sample size \(n=1000\).
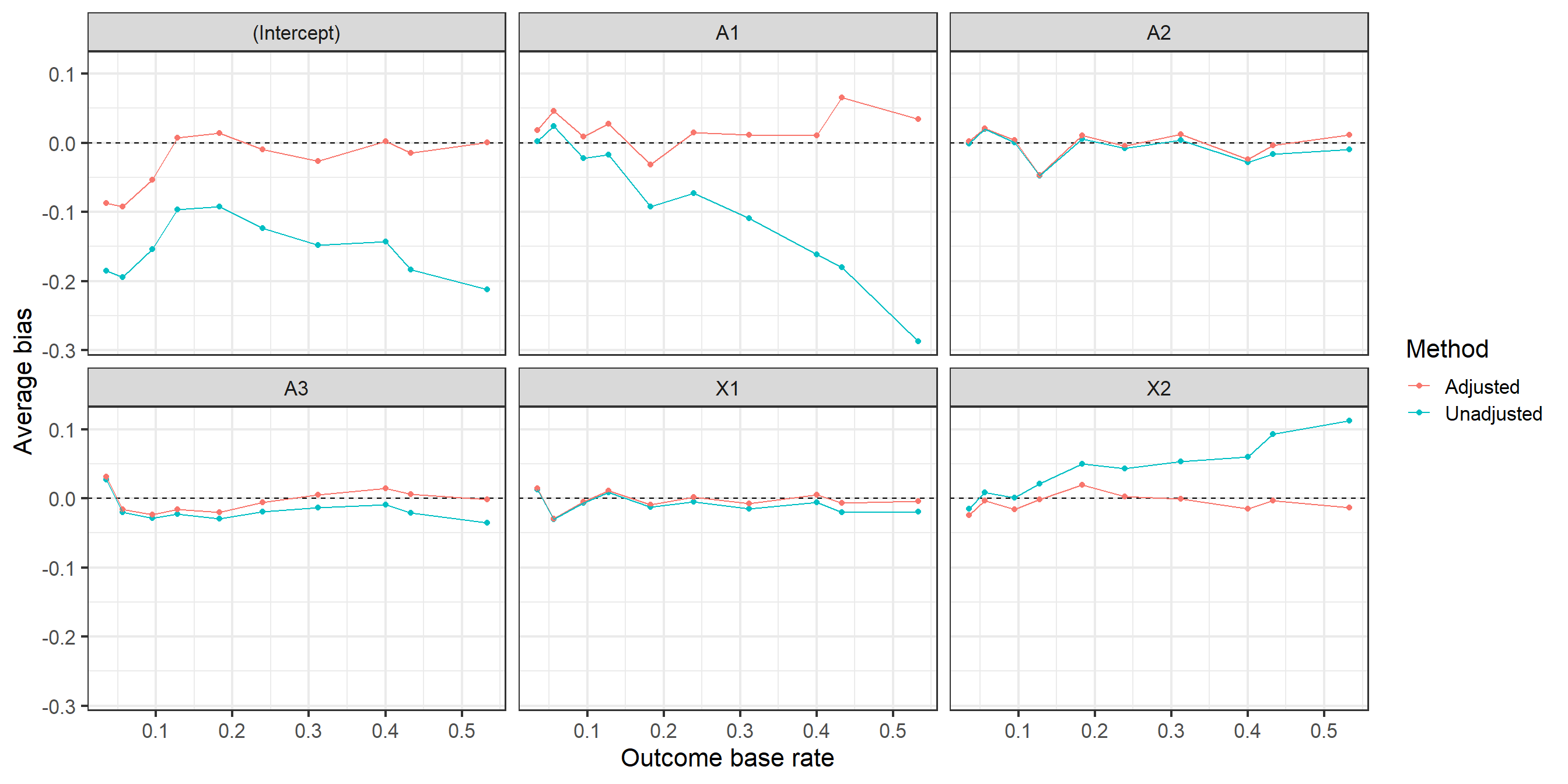
Below we assess the extent to which the degree of bias varies by the outcome base rate. We see that the degree of bias, and importance of using bias-correction matters more when the \(Y=1\) is more likely for the current simulation setup.
In this situation with nondifferential misclassification error and knowledge of the sensitivity and specificity of the measurement process the outlined method works well, demonstrating a reduction in coefficient bias that varies from small to considerable depending on aspects of the data generation process (outcome base rate) and degree of mismeasurement.
References
Shaw, Pamela A, Paul Gustafson, Raymond J Carroll, Veronika Deffner, Kevin W Dodd, Ruth H Keogh, Victor Kipnis, et al. 2020. “STRATOS Guidance Document on Measurement Error and Misclassification of Variables in Observational Epidemiology: Part 2—More Complex Methods of Adjustment and Advanced Topics.”Statistics in Medicine 39 (16): 2232–63.